The majority of people visiting a news website don’t care about the front page. They might have reached your site from Google while searching for a very specific topic. They might just be wandering around. Or they’re visiting your site because they’re interested in one specific event that you cover. This is big. It changes the way we should think about news websites.
We need ambient findability. We need smart ways of guiding people towards the content they’d like to see — with categorization and search playing complementary goals. And we need smart ways to keep readers on our site, especially if they’re just following a link from Google or Facebook, by prickling their sense of exploration.
Pete Bell recently opined that search is the enemy of information architecture. That’s too bad, because we’re really going to need great search if we’re to beat Wikipedia at its own game: providing readers with timely information about topics they care about.
First, we need to understand a bit more about search. What is search?
Full-text search is a last resort
Rack your brain for a minute. You’re searching for a document in a repository. That repository might be the web, it might be an intranet or it might be content from your local news outlet. You’re using the search box we’re all familiar with. I now ask you if you’re looking for results that contain the words that make up your query. You give me a quizzical look and answer: why, that’s the point! But you’re wrong.
When somebody enters the query Tony Blair, they’re not looking for news articles that contain the words Tony Blair, they’re looking for news articles and assorted other information relating to Tony Blair. Tony Blair, the person, not Tony Blair the string of letters. They’d be happy to see a biography for Blair, for instance. Or an opinion piece written by the former Prime Minister. Or maybe they’re just searching for content about Labour from 1997 to 2007 when Blair was the PM.
Let’s make a small but important distinction. There’s relevance , and there’s occurrence. When you perform a search, you’re looking for relevant content. A strong indicator of relevance is whether or not the words you’re searching for occur in the result set, but that doesn’t make relevance and occurrence the same thing.
A good search engine goes beyond occurrence, by stemming and by being aware of synonyms. The latter means simply that a search for illnesss hould also match documents about disease unless you specifically tell the search engine you prefer to see only exact matches. Stemming means that a search for disaster happened before should also match documents that contain a sentence like “Disaster happens every so often, we’ve seen it before.” Happens is not a part of that query, but it’s what you were looking for.
Google is amazing at this sort of thing. Most search engines you’ll see on news websites aren’t. But they should be, because although Google is in a whole ‘nother league, stemming and synonym-awareness is a solved problem: text indexers like Lucene do it very well.
But a good search engine that blazes through enormous quantities of text is not good enough. Remember, oftentimes you’re not even searching for text, you’re looking for things.
- If somebody searches for
economythey’re probably looking for stories categorized or tagged undereconomy. - If you search for
Birminghamon a news website, you’d like to see all the news that has a link to the greater Birmingham area. Considering that this is an area, maybe the best way to present these results would be as a map and not as a list of results. More about that later. - If you search for
Randy Newman about musicianshipyou’ll want to see all the content where Newman talks about his own and other people’s music, and what would be really kick-ass is if the search engine wouldn’t return stories but instead would present you with just those parts of the matched documents that are relevant. And those fragments most likely won’t even contain the wordmusicianship, even though they’ll be about musicianship.
Some of these wishes are a bit too wild for current technology. But provided you have a solid information architecture in place (hint: this and this and this and this), creating a great search experience is well within the realm of possibility. We’ll take a two-pronged approach: we’ll try to improve search by not searching, and we’ll also try to make things better for those times when our readers really do want to or have to search to find what they need.
The Sadness of Search
Our readers often don’t know exactly what they’re looking for. Perhaps more importantly, people who land on on our site from Google don’t know about all the great similar content they could find if only they’d stick with our site for just a bit longer. Which is why most news websites still generate no more than a measly 15 pageviews per unique visitor per month. We need to get readers to the content they would like to see as fast and as effortlessly as possible, keep them engaged for longer when they’ve found that content, and point them in the right direction when they ask for either context, related or similar content.

Getting people to the content they want to see, using the search functionality your average newspaper website has on offer, is not exactly what I’d describe as fast or effortless. Full-text search can be a daunting experience.
Poor search wastes time like a crooked street sign that sends us in the wrong direction. It erodes trust, derails learning, and confuses decisions. It makes us blame ourselves. […] We feel sadness, shame, anger, and disgust. Sometimes, we soldier on, unhappy but resolute. Often we surrender. We simply fail to search. We live uninformed without seeing what we miss (Peter Morville and Jeffery Callender, Search Patterns, p. 19)
Full-text search is the web equivalent of searching for your keys. They could be anywhere. Your surroundings give no indication whatsoever of where they are to be found. Keys are small so it’s like finding a needle in a haystack. Before long you’ll be second-guessing yourself and kicking yourself in the head because you probably didn’t search your jacket pockets thoroughly enough. Even though you’ve rummaged through them twice, earlier. Ahhhrr.
As I mentioned, we can try to make full-text search as palatable as possible, but part of our strategy should be to make search superfluous in most scenarios where people hope to find more or other information on a certain topic. That means preemptive contextualization, blended search-and-navigation, and assorted methods that humanize the search experience.
Preemptive contextualization
Preemptive contextualization. Whew, now that’s a mouthful. What it comes down to is that search is often very predictable : people search for the same kinds of things, and have the same kinds of questions. Predictable means avoidable. Don’t make people use a search engine to get answers to questions like:
- I’ve just read this great article by Chris Anderson. That guy is on to something. Can I see more stuff written by Chris?
- Great piece on the rat race for admission to an Ivy League institution . Where can I find similar stories about higher education?
- This story about the recent political crisis in Belgium reads like a follow-up to some earlier reporting. Link me up!
Most news websites don’t even provide a quick link to the portfolio of the author of the piece you’re reading?
- MinnPost doesn’t,
- The Voice of San Diego doesn’t,
- The Los Angeles Times doesn’t, and
- Le Monde doesn’t either.
The Texas Tribune does. Seriously, do you really need to be a Pulitzer-prize winning developer or have the genius of the New York Times to realize people might want to check out more stories or opinion pieces by the same author after they’ve read a story they like? Do you really expect them to copy-paste the name of that author into a search box and pray for the best?
We can preempt search in a number of ways. One of the most obvious site-wide improvements we can make is to fashion a good information architecture in the narrower sense of that term, namely IA as a way of structuring content and constructing navigation on top of that. We need kick-ass navigation: superb primary navigation (what we’ll present as the basic sections of our site) and complementary secondary ways of navigating the site (browsing by author, by topic and so on).
Primary navigation and secondary navigation should go together like toast and butter, and the final scheme should be based on
- the nature of your content
- what kinds of user interaction you expect or want to encourage
- analytics that give insight into how users click through your site
- AB-testing to make sure any enhancements you make along the way actually work

Most improvements we can make with preemptive contextualization are not site-wide, however, but depend on the kind of page that prompted the (type of) question in the first place. We should evaluate and enhance each type of page separately, and think about frequently asked questions we need to suggest the answers to, even before readers have asked these questions. The homepage is becoming less important than it used to be, but it still gets a huge amount of traffic that we can’t afford to mess with. Here are some common questions on the homepage:
- Wow, I’m overwhelmed. What’s on offer? Do you have a map? — We need some sort of a sitemap that acts as a gateway to our content and is broader than our primary navigation.
- Hmm, do you happen to have any reporting about banking reform? I thought that was all over the news? — We need deep links to the topics that are currently on people’s mind and that are being talked about.

Topic pages (e.g. about a person) should be able to quickly display and filter associated content by
- content type or medium: video, audio, text, data
- genre: interviews with that person, opinion pieces by or about that person, the positive or negative stories about him or her.
- related content: the organizations this person belongs to, events in which he or she has played a role
Story pages are obviously the most important part of our website. We can answer a lot of questions for our readers here:
- Eh, I don’t understand this! — We need links to terms on Wikipedia (e.g. using Apture) or the ability to look things up in a dictionary (like the one they have over at the New York Times)
- Interesting piece, can you tell me a bit more about the shady organization that is mentioned in this story? — We need quick links to topic pages about related persons, organizations, events and locations.
- Mm-mm. I do love these long New Yorker-style features that seem to go on forever. More, please! — We need links to content in the same section or of the same genre or mood.
Do mind that if you include related content, make sure it doesn’t suck. I’ve had it up to here with “related content” boxes on news websites that are nothing more than automated searches for related content based on “significant keywords” in the content. It doesn’t work. Everybody hates it, it’s crap. If you really really must have it, use Evri, which is halfway bearable. But try to do things the right way.
Related content should be referred to either using tags or if you’re really hip, using relationships. These lists, while they don’t have to be entirely hand-crafted, should have a human touch. Explicitly linking back to previous reporting on a certain topic is still the only reliable way of indicating follow-up pieces and previous reporting.
And instead of naming it “related content”, try these instead: “more in this section”, “other opinion pieces from this author”, “earlier reporting on this subject”.

Blend search and navigation: faceted search
All of the suggestions above improve findability and reduce frustration by replacing search with navigation.
But there’s an entire gray area between search and nav as well, as Peter Morville points out in Search Patterns. After all, even something trivial like browsing a list of items within a category to see what you’d want to read is search behavior too. Search behavior doesn’t always revolve around a big input box and a submit button.
If we can’t preempt search, maybe we can improve the experience by providing interfaces that are 50% search, 50% navigation. It’s pretty much unexplored territory, though.
Faceted search is probably the blended experience you’re most familiar with. Enter a search query, and then refine the results using a dynamically generated menu.

But nothing’s for free. Faceted search needs facets: ways of splitting up search results into meaningful categories. Rich metadata and a well thought-out categorization scheme is a prequisite.
Humanizing search
Suppose you’d ask Steven Levy, “so, have you written anything about Google lately?” “Well, yes”, he’d respond, “I’ve just written a cool piece about their search algorithm for Wired!” And the natural follow-up would be something like: “So, you’re looking for stuff about Google, eh? Have you read What Would Google Do by Jeff Jarvis? That’s a good place to get started.” See how natural that feels? First and foremost, we want to know about matches to our exact query. But because most of the time we don’t really know what we’re doing or what to expect when we enter a search, a helping hand that senses what we might have meant and gives additional suggestions is exactly the ticket.
If somebody would ask me, “I think you’ve written something about structured content and serendipity, isn’t that so?, my answer would be “Ah, no, you’re quite mistaken. You must’ve read my article We’re in the information business and clicked on the link to Adrian Holovaty’s A fundamental way newspaper sites need to change . Here ya go, “let me link you up.”
Online search should work similarly to asking a question to a flesh-and-blood reporter. I don’t mean to exalt answering engines like AskJeeves or WolframAlpha. I mean that search should incorporate some basic elements of what it’s like to ask a human for a question, and for another human to give an answer:
- Flexible scoping. If you insist on an exact answer, you’re going to get one (or none, if we don’t know the answer), but otherwise we’ll try our best to give an answer to a variation that we can answer.
- Broad scoping. It’s not because you ask me a question, that I have to provide the answer off the top of my head or that the answer must be something I’ve personally said or written. If I know of a book, a magazine or an article that’s a good match for your query, I’ll point that out. Getting the answer is what counts, wherever we find it.
- Knowledge of intent and context. We get what we’re getting at. We try to grasp the intent behind a question and return results that might be helpful even if they’re not a direct answer to your question. We go beyond the precise question and, thank God, beyond the precise terms used in formulating that question.
Applying these abstract principles to online search might seem to require voodoo or sci-fi-style artificial intelligence, but actually, it doesn’t. There are a few feasible ways in which we can humanize our search engines.
Best bets
Maybe we can’t preempt search entirely, but then we can at least cut it short and provide quick answers to common answers so readers don’t have to scan the dreary lists of content returned by our search engine. They still can, if they’re not happy with our preformulated answer or Editor’s Choice, but most of the time our preselection will be all a user needs.

Best bets are easy to implement, as long as you have search analytics. If you do, it’s only a matter of taking the ten or twenty or fifty most common queries, hand-picking the most relevant content from your website, and displaying those picks above the regular search results. You can even implement this on top of a Google site search engine, if your site doesn’t have its own engine.
We’d be foolish if we thought that best bets provide us with real knowledge of intent and context”, because we don’t know the first thing about the users that are doing the searching. We don’t know what their existing knowledge or “read-state is like, we don’t know their mood, we don’t know what keeps them up at night. But while we can never really understand a search query, hand-crafted human responses to common search queries do go a long way towards solving search-related usability problems.
Broad framing
Topic pages about persons, organizations, locations and events are great ways to answer general inquiries by readers. After all, if you have these kinds of pages, you probably spend hours and hours to get them just right and to keep them up to date, hoping that your readers will get something out of them.
A lot of search behavior stems from an attempt at learning. So another way of cutting search short is by trying to ascertain what a query is about and then, in addition to the full-text search, providing quick links to relevant topic pages. Words like financial meltdown as part of a query are a pretty good predictor that we’re looking for information about economics, finance and the global financial crisis. Chances are these pages will be way more valuable to me than a bunch of links to articles that contain the exact words financial meltdown.
Even if plain-Jane full-text search was all a reader came in for, the invitation to learn more about broader topics might be too enticing to pass up. Isn’t that exactly the Wikipedia-style exploratory browsing (or wilfing) we’re so jealous of?
The simplest way of doing quick links to related topics would be to simply boost the relevance of the ‘topic’ content type while configuring the search engine. That way these pages will end up at the top of a lot of search results. Most any search engine is configurable in this way.
Another way to accomplish these related links to high-value topics pages, one that’s a bit more refined, would be to programmatically aggregate the themes/topics of each search result (you do have that sort of metadata, don’t you?) and serve up the topic pages related to the themes that recur most among the results. One advantage over simply boosting the relevance of topic pages would be improved accuracy. But more importantly, this approach allows for more freedom in designing the experience, for example by putting these references to broader topics in a separate box to the right of the regular results, or by allowing you to display these topic pages by type (person, organization, location, event).
Further improvements to the accuracy and usefulness of such ‘broad framing’ could probably be achieved by analyzing the semantic sphere (the aboutness”) of the query and to take it from there. Bringing “natural language analysis into the picture would allow us to go beyond the precise words of the query and instead get a feel for its intent and meaning when suggesting related topics. A vague feel, yes — machines and language are still a tricky combo — but maybe it’s stuff that we can use.
Even basic versions of this pattern have the potential to enrichen the search experience for a sizable amount of search queries, i.e. all queries that are exploratory and don’t have a precise intent.
Entity extraction
I mentioned before that we hardly ever really search for text: we search for information about Steve Jobs, news nearby our home town, all content that has something to do with climate change and so on.
Our search engine should be smart enough to extract these entities and use them to enhance the results we get back:
- If a query contains a date, we could display relevant events within that date range, either textually or in a timeline.
- If a query contains the name of a person, a link to the biography of that person should be the first result people see. (If we have that biography on hand, that is.)
- If a query contains a place name, we could display relevant results on a map centered on that location
Services like OpenCalais and Yahoo! Placemaker make entity extraction easy on us developers, by doing all the heavy lifting so we don’t have to.

Do note, though, that the more heavily tagged and structured your content is, the more advantage you can take of entity extraction. You can’t return a biography as the first result in a query, if that biography is not in any way differentiated from regular news stories. You can’t do location-aware search if you don’t store the relationships between news stories and locations. Enhancing search often means enhancing the content that provides the raw material for your search engine; you can’t turn lead into gold.
Wisdom of the crowd
Flickr has a lot of photos, but finding exactly what you want to see can be hard. Most of the time, search is a back-and-forth experience that involves multiple rounds of refining and tweaking the query. What if we could use the research, the specific tweaks and refinements to the original query, and use that data to inform the search of another user? That’s exactly what Flickr does.
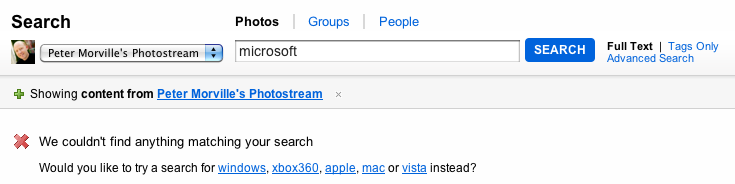
If you’d search Peter Morville’s photostream for microsoft you won’t find any results, but Flickr knows from the search behavior of its users that a query for microsoft is often tweaked to windows, and when those users click through to photos in that second result set, Flickr knows that this second attempt was probably a success: they’ve found what they needed. This works very similarly to how human beings search for things:
Steven: I can’t seem to find a good shop to buy these Adidas Millenium Falcon shoes. I’ve scoured three stores already with no luck.
Jon: Yeah, but those shoe shops along Columbus Avenue are a bad bet for sneakers. Have you asked Ted? He went looking for those same ones last week, and I think he found some.
So another neat little way of reducing frustration with search, although one that requires a significant engineering effort, is to tool your search engine to learn from the aggregated behavior of its users.
I want it all!
Okay, so we’ve talked about some ways in which we can improve the user experience during search. What we haven’t talked about is what our site should be searching. Again, this might seem to merit a simple answer: why, the full text of our content, of course! But we can do better than that.
Imagine me surfing your news website. I’m interested to know more about a person or a location or an organization. Since I’ve decided that I want to search on one specific site, yours , rather than via Google, you can safely assume I want to narrow my search and that I don’t want to search the entire web. I want to know what your site has to say about whatever it is I’m searching for. But what does that mean?
Not just stories and text
Don’t forget about all the content that is available on your own site, yet often doesn’t get indexed. There’s a nascent movement towards journalists providing (wherever possible) their original research material, allowing readers to explore a subject as fleetingly or as deeply as they want. These Word and PDF files need to be searchable as well, yet often they aren’t. There are open-source tools to return plain-text renditions of Word and PDF documents, and optical character recognition (OCR), while not there yet, is getting better and better. DocumentCloud also allows people to easily annotate these kinds of source documents.
So a great search engine would know about all the cool stuff your site has to offer, not just about the news reports in your database. Here’s a very incomplete list of things that should be searchable:
- news items
- documents (if necessary using OCR)
- video and audio (using transcriptions)
- topic pages, and assorted other content types that are not stories
- comments
- photographs (using tags)
- events (using dates)
What’s really ours: the border between your site and the rest of the internet
With the role of curation and link journalism growing ever more important in journalism, what a site has to say is no longer limited to the content that lives on your own webserver. Good content links to articles and blog entries and documents all over the web. That content doesn’t exist on your site, but for your readers you’re the gateway to that content, and they should be able to find it not only when linearly reading an article, but also when they’re searching on your site.
Now here’s the thing: if we index documents and other source material, why don’t we index the content of links to other websites as well? They’re source materiaal just the same. By curating, your site gives those links meaning. They’re part of your offering and they should be searchable just like your own content is.
We want to design search that is not merely adequate but search that’s excellent. Excellence means thinking in terms of user experience. When we think of search as a way for users to explore all our varied offerings, the border between your site and the rest of the internet becomes extremely vague. Perhaps we shouldn’t just include external webpages we’ve linked to in our search repository, but RSS-feeds from people and organizations we cover as well?
Users expect a search engine to search the site they’re on, so we shouldn’t stray too far from that convention. However, when implemented wisely, and with good visual cues that make it easy to tell apart external content from your own, it can make sense to open up your search engine a bit, and allow it to return meaningful results not just from your own website, but from that part of the web and those topics you cover.
There are two big tools that can help us index other parts of the web that are relevant to our own site.
- Web crawlers. A crawler can visits the links in our own content and adds them to our index.
- Search APIs. We can do clever things using the power of the Google, Yahoo! and Bing search APIs.
Searching a bigger part of the web than just your own website requires storage and processing power, as well as a good design to separate your own content from relevant content from elsewhere. Aside from that, it’s hardly rocket science.
Humanizing search means a search engine should be able to give answers to the question “what’s happening?” rather than just narrowly answering “what is on this site?”. That said, it will take a lot of experimentation to find the right balance.
Side note: beware
On a side note: beware of some of the newer tools in the reporter’s toolbox. Apps like Scribd and CoverItLive store documents and text on their own servers, which makes them inaccessible to your own search engine, unless you go to the additional effort of integrating with their APIs. That is, if they actually have an API you can integrate with. Keep your archives intact and complete. Think about search before deciding to use any of these services. The goal is to index more content than you currently do, not less!
Searching is learning
Search doesn’t have to be awful, but it’s never going to be exactly fun to skim through tens of hundreds of supposedly “relevant” results to our query, hoping to find the ones we’re looking for. We can make things better by allowing readers to quickly narrow down their search using rich facets. We can support those readers who happen to be in an exploratory mood by adding smart secondary navigation by genre, topic, location and medium. We can answer questions readers might have about a certain piece of content before they even ask them, preempting search.
When solid navigation, alternative ways of browsing and prefab answers to common types of questions aren’t enough and people do have to use the search engine, it’s only proper that we make the experience as painless and human as possible. It’s going to be hard, but we should try to learn our search engine to understand the meaning and intent behind each query.
Search engines on news websites should make helpful suggestions about content you might want to check out, even if you didn’t explicitly search for it.
Search engines should guide readers to topic pages that provide excellent introductions to important parts of your coverage, like the broader context behind events, biographies, company profiles and so on. More importantly, we should guide readers to topic pages because they’re among the best gateways to your reporting. Definitely better than search.
And we make sure to avoid uncharted territory that doesn’t show up in our search indexing not only our stories, but sources and documents as well.
Newspapers try to help their readers in making sense of the world. When we see readers exploring and searching, we see them at a crucial point in time: a moment when they’re ready, willing and eager to learn. The power to turn exploration into learning is the most wonderful gift we can give to our readers. We should help readers on their quest for knowledge. Retooling navigation and search is a worthy first effort.
share on twitter
Findability and Exploration: the future of search debrouwere.org/1h by @stdbrouw
Stijn Debrouwere writes about statistics, computer code and the future of journalism. Used to work at the Guardian, Fusion and the Tow Center for Digital Journalism, now a data scientist for hire. Stijn is @stdbrouw on Twitter.